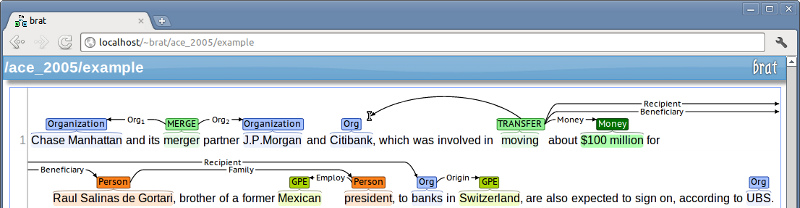
Semantic Category Disambiguation (SCD)

Figure: Demarked spans
Pontus Stenetorp, Sampo Pyysalo, Sophia Ananiadou and Jun’ichi Tsujii
—
Aizawa Laboratory, University of Tokyo, Japan
University of Manchester, United Kingdom
National Centre for Text Mining, United Kingdom
Microsoft Research Asia, People’s Republic of China
Nanyang Technological University, Singapore, December 15th 2011
Figure: Demarked spans
Figure: Demarked spans

Figure: Annotated spans
| Corpus | Semantic Categories |
|---|---|
| BioNLP/NLPBA 2004 Shared Task Corpus (NLPBA) | 5 |
| Gene Regulation Event Corpus (GREC) | 6 |
| Collaborative Annotation of a Large Biomedical Corpus (SSC) | 4 |
| Epigenetics and Post-Translational Modifications (EPI) | 17 |
| Infectious Diseases Corpus (ID) | 16 |
| Genia Event Corpus (GE) | 11 |
Table: Corpora used for experiments
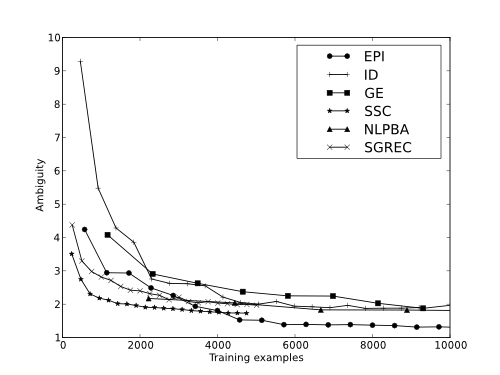
Figure: Ambiguity per Dataset
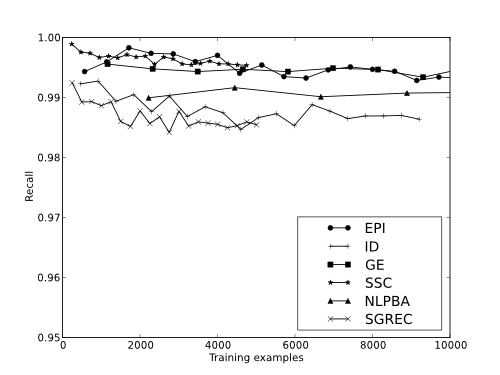
Figure: Recall per Dataset
| Data set | μAmb. | Amb. | μRecall | Recall |
|---|---|---|---|---|
| EPI | 1.8/89.4% | 1.3/92.4% | 99.5% | 99.4% |
| ID | 2.9/81.9% | 1.9/88.1% | 98.8% | 98.6% |
| GE | 2.1/80.9% | 1.7/84.5% | 99.4% | 99.5% |
| SSC | 2.0/50.0% | 1.7/57.5% | 99.6% | 99.5% |
| NLPBA | 1.8/64.0% | 1.6/68.0% | 99.1% | 99.1% |
| SGREC | 2.4/60.0% | 2.0/66.7% | 98.7% | 98.6% |
Table: Performance averages and for the final data point for each dataset